爬取数据
jsoup包,来进行解析网页
tika包来爬电源爬图片
public class HtmlParseUtil{
public static void main(String[] args){
// 等你看完这节,你就会发现Jsoup你以前见过,就是Java中的css选择器
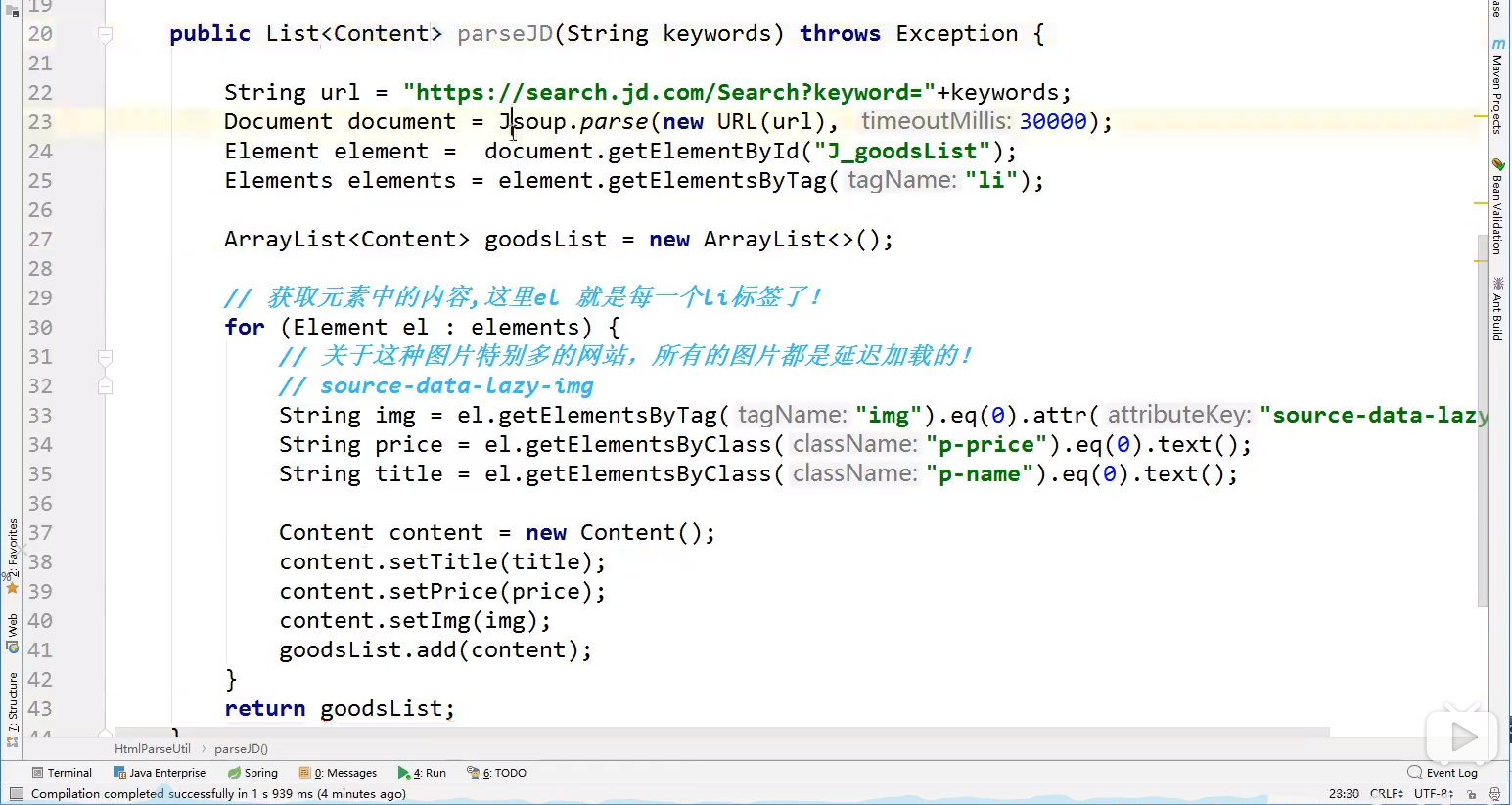
// 获取请求 https://search.jd.com/Search?keyword=java
// 前提,需要联网!
String url = "https://search.jd.com/Search?keyword=java"
// 解析网页(Jsoup返回Document就是浏览器Document对象)
Document document = Jsoup.parse(new URL(url),30000);
// 所有你在JS中的方法,这里面都可以用
Element element = document.getElementById("J_goodsList");
// 获取所有的li元素
Element elements = element.getElementByTag("li");
// 获取元素中的内容,这里el 就是每个li标签了!
for(Element el : elements){
// 关于这种图片特别多的网站,所有的图片都是延迟加载的!
// source-data-lazy-img
String img = el.getElementByTag("img").eq(0).attr("src);
String price = el.getElementByClass("p-price").eq(0).text();
String title = el.getElementByClass("p-name").eq(0).text();
System.out.println(img,price,title);
}
}
}
懒加载,为了让页面刷新速度变快
所以直接在页面中是拿不到里面的jd的大图的
加上可以自定义的keywords
再定义一个实体类
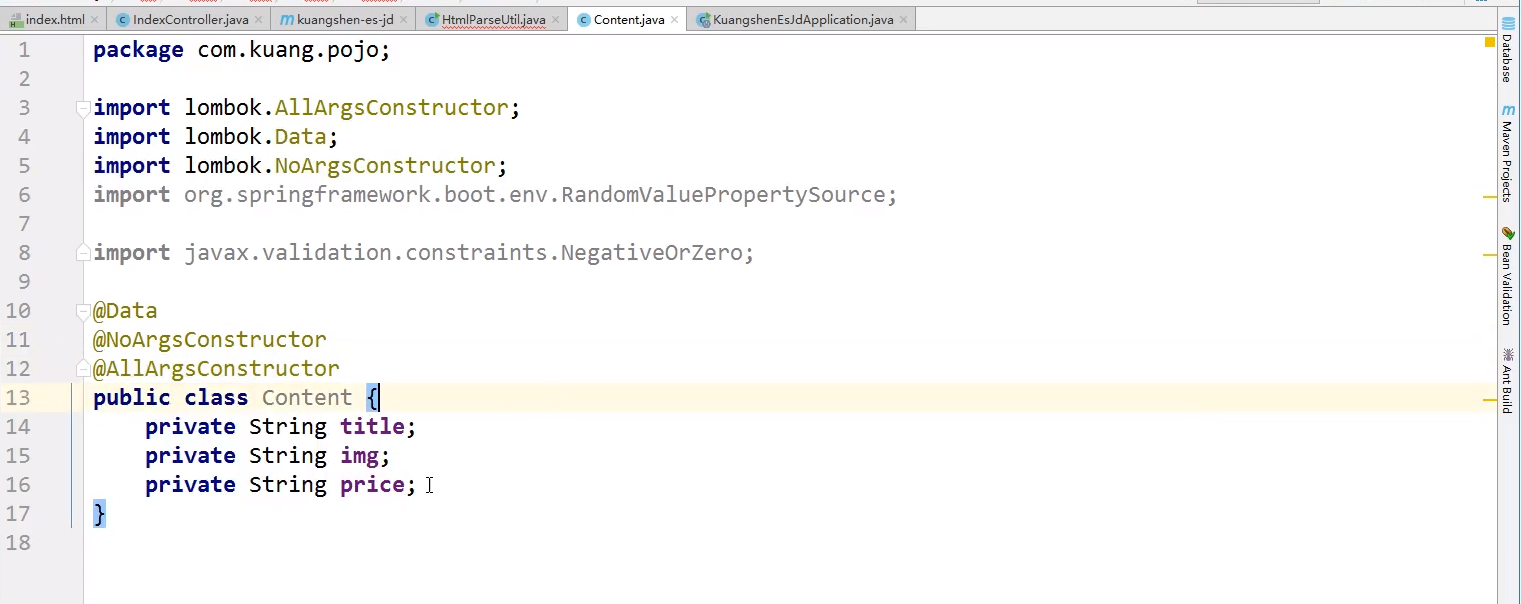
上面可以自己添加属性
执行工具类

可以搜索到
如果要支持中文
需要设置url解析,charset的参数
配置