聊聊DougCutting
为什么要讲这个人,后面要聊大数据
本故事内容来自公众号
1998年9月4号,google公司在美国硅谷成立.正如大家所知,它是一家搜索引擎起家的公司

无独有偶,一位名叫DougCutting的美国工程师,也迷上了搜索引擎.他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene.

Lucene使用Java写的,目标是为各种中小型应用软件加入全文检索功能.因为好用而且开源(代码公开),非常受程序员们稀罕)
在这个过程中,google确实找到了不少好的办法,并且无私地分享了出来.
开源是一种精神!
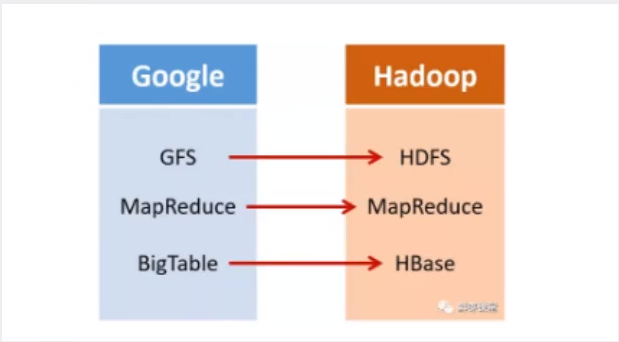
2003年,google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(google File System).这是google公司为了存储海量搜素数据而设计的专用文件系统
第二年,2004年,Doug Cutting基于google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)
还是2004年,google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型.这个编程模型,用于大规模数据集(大于1TB)的并行分析运算.
2005年,Doug Cutting 又基于MapReduce,在Nutch搜索引擎实现了该功能.

2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting

截图
我们继续往下说.
还是2006年,google有发表论文了
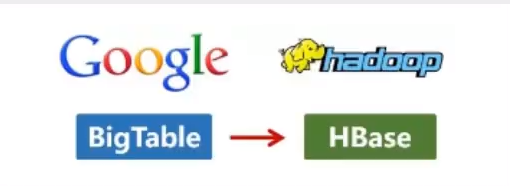
这次,他们介绍自己的BigTable,这是一种分布式的数据存储系统,一种用来处理海量数据的非关系型数据库.
Doug Cutting 当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase.
好吧,反正就是紧跟Google时代步伐,你出什么,我学什么
所有,Hadoop的核心部分,基本上都有Google的影子.
2008年1月,Hadoop成功上位,成为Apache基金会的顶级项目.
同年2月,Yahoo宣布建成了一个拥有1W个内核的Hadoop集群,并将自己的搜索引擎产品部署在上面.
7月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,用时209秒.

生存法则: 不断学习(虚心学习! ) 优胜劣汰!
三体里面的片段
会到主题
Lucene是一套信息检索工具包!jar包! 不包含搜索引擎系统!Solr
包含的是索引结构!读写索引的工具!基本的常用的网站搜素排序功能,搜素规则功能...工具类!
Lucene好elasticsearch的关系:
Elasticsearch是基于Lucene工具包做了一些封装和增强(我们上手是十分简单!)
HashMap比这个难多了
讲课风格:学习更多的是培养大家的学习兴趣!
教学风格:开源,免费,授人以鱼